|
Junseok Kim (Andrew) Hello 👋! I am a Ph.D candidate at Seoul National University, advised by Prof. Kyomin Jung. My research interests lie in the areas of natural language processing and multimodal learning, with a focus on improving the reliability and reasoning capabilities of large language models. Email / Google Scholar / Github / Linkedin |

|
News
|
ResearchMy research investigates 1) why large language models sound confident when they should not, and 2) how to make them reason and decide more reliably. I study inference strategies that allow models to regulate their decision processes based on confidence or response quality, rather than treating all responses as equally informative. To understand why such strategies succeed or fail, I increasingly focus on mechanistic interpretability, analyzing how internal representations influence evidence use in multimodal models and how these mechanisms can be adjusted to support more reliable reasoning |
|
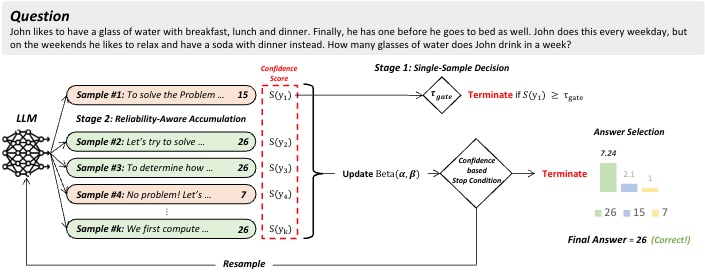
Reliability-Aware Adaptive Self-Consistency for Efficient Sampling in LLM Reasoning
Junseok Kim, Nakyeong Yang, Kyungmin Min, Kyomin Jung arXiv, 2026 paper We propose Reliability-Aware Adaptive Self-Consistency (ReASC), an adaptive self-consistency framework that incorporates a response-level confidence as a reliability signal to guide how evidence is accumulated at inference time. |
|
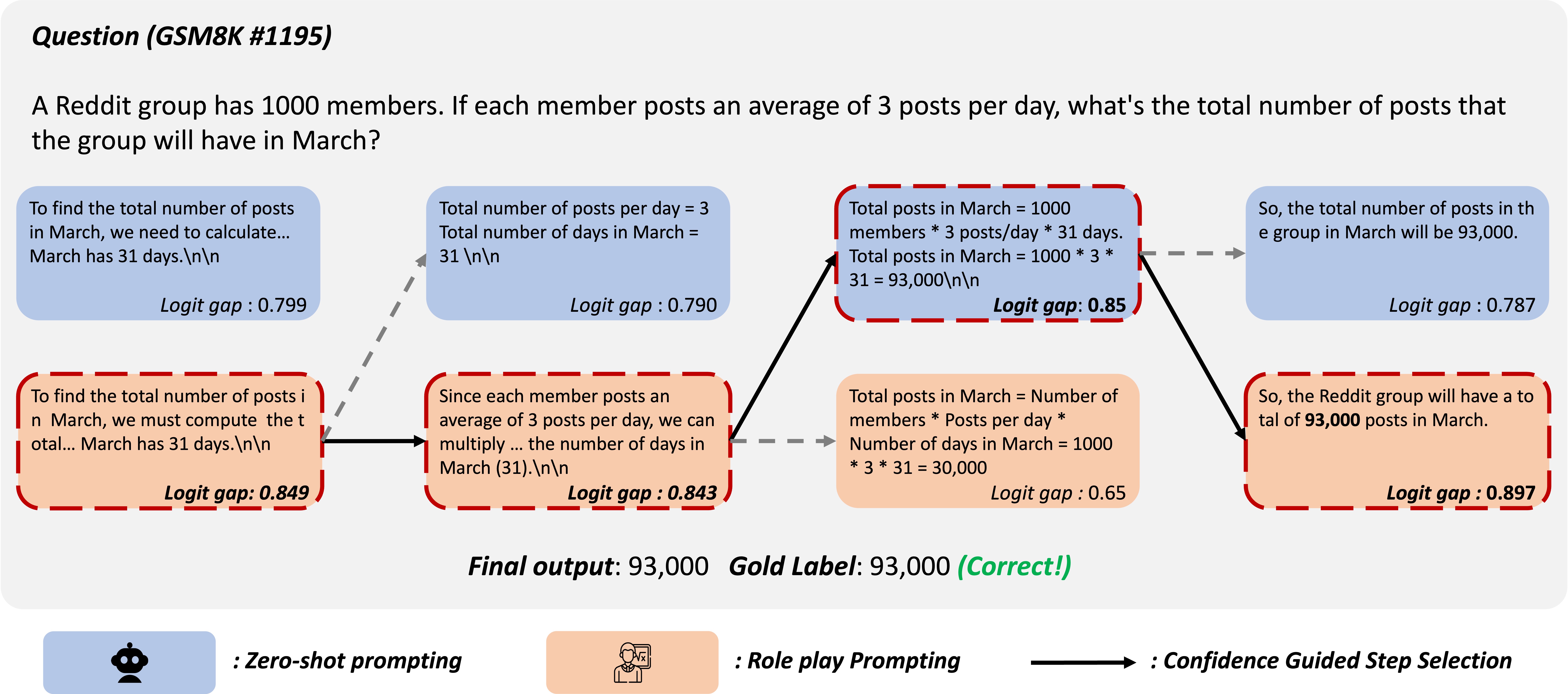
Persona Switch: Mixing Distinct Perspectives in Decoding Time
Junseok Kim, Nakyeong Yang, Kyomin Jung Findings of EACL, 2026 paper / code Persona Switch is a training-free decoding method that improves reasoning by step-wise switching between zero-shot and role-play prompting based on token-level confidence at decoding time. |
|
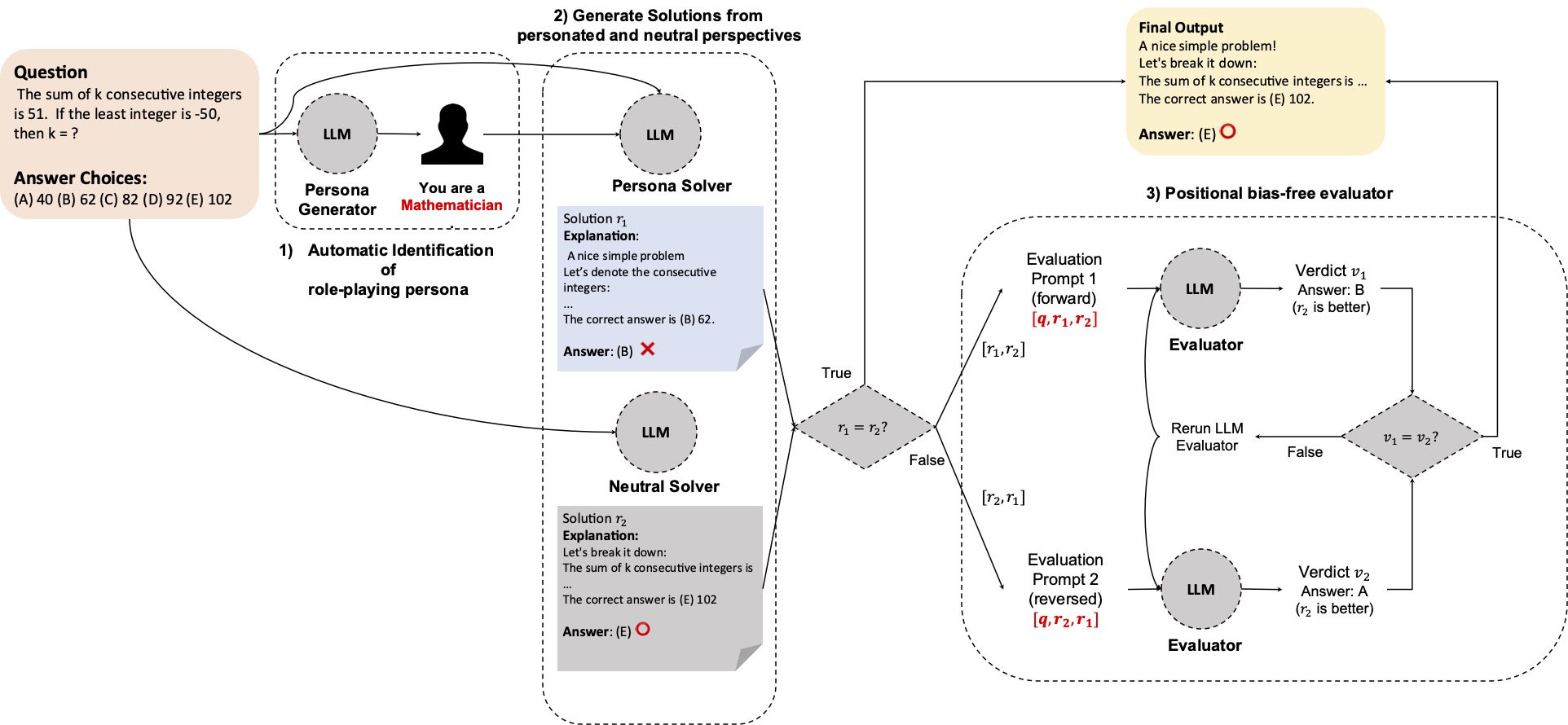
Persona is a Double-Edged Sword: Rethinking the Impact of Role-play Prompts in Zero-shot Reasoning Tasks
Junseok Kim, Nakyeong Yang, Kyomin Jung Findings of IJCNLP-AACL, 2025 paper / code We analyze the impact of role-play prompts in zero-shot reasoning tasks and show that they can be detrimental to performance in some cases depending on the designed persona. |
|
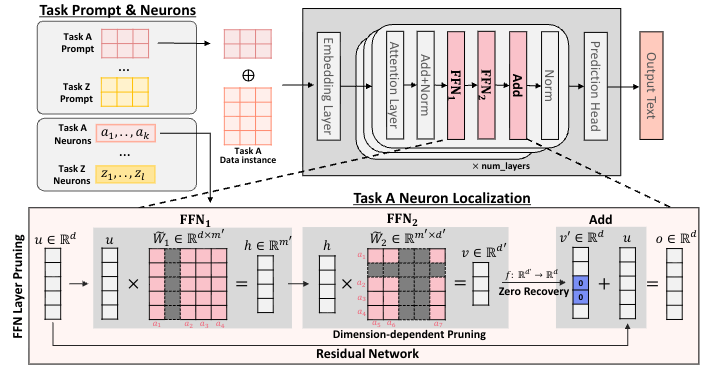
Unplug and Play Language Models: Decomposing Experts in Language Models at Inference Time
Nakyeong Yang, Jiwon Moon, Junseok Kim, Yunah Jang, Kyomin Jung CIKM, 2025 [Oral] paper We introduces "Decomposition of Experts" (DoE), a framework that accelerates inference by dynamically identifying and activating only task-specific neurons within a language model to reduce computational costs without sacrificing accuracy. |

|
Last updated in February 2026. This page is based on Jon Barron's website template. |